人工智能(AI)作為當今技術(shù)發(fā)展的核心驅(qū)動力,其背后依賴著堅實的數(shù)學理論與軟件開發(fā)實踐。在眾多數(shù)學工具中,假設(shè)檢驗作為統(tǒng)計學的重要分支,為AI系統(tǒng)的決策與模型驗證提供了理論支持。本文將探討假設(shè)檢驗在人工智能基礎(chǔ)軟件開發(fā)中的作用,并分析其實際應(yīng)用場景。
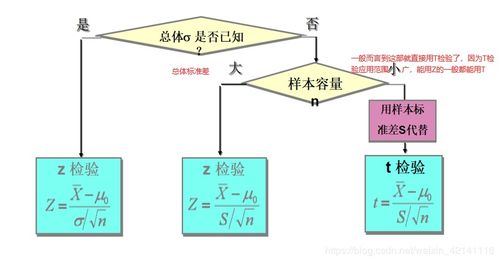
假設(shè)檢驗是統(tǒng)計學中用于判斷某個關(guān)于總體參數(shù)的假設(shè)是否成立的方法。它通過收集樣本數(shù)據(jù),計算檢驗統(tǒng)計量,并與臨界值比較,從而決定是否拒絕原假設(shè)。在人工智能領(lǐng)域,尤其是在機器學習和數(shù)據(jù)分析中,假設(shè)檢驗被廣泛應(yīng)用于模型評估、特征選擇和算法比較。例如,在開發(fā)分類模型時,研究人員常使用t檢驗或方差分析(ANOVA)來判斷不同特征對模型性能的影響是否顯著。
假設(shè)檢驗在人工智能基礎(chǔ)軟件開發(fā)中扮演著關(guān)鍵角色。在構(gòu)建AI系統(tǒng)時,開發(fā)者需要驗證模型的可靠性和泛化能力。假設(shè)檢驗可以幫助評估模型在測試集上的表現(xiàn)是否優(yōu)于隨機猜測,或者比較不同算法的性能差異。舉例來說,在A/B測試中,假設(shè)檢驗用于確定新算法是否顯著提升了用戶體驗或業(yè)務(wù)指標。在異常檢測系統(tǒng)中,假設(shè)檢驗可用于識別數(shù)據(jù)中的離群點,從而提升系統(tǒng)的魯棒性。
從軟件開發(fā)的角度來看,將假設(shè)檢驗集成到AI基礎(chǔ)框架中,能夠提高開發(fā)效率和系統(tǒng)質(zhì)量。許多流行的AI庫,如Python的Scikit-learn和StatsModels,都內(nèi)置了假設(shè)檢驗功能,允許開發(fā)者快速執(zhí)行統(tǒng)計測試。例如,在特征工程階段,開發(fā)者可以使用卡方檢驗來評估分類變量與目標變量的相關(guān)性,從而優(yōu)化特征選擇流程。同時,在模型部署后,假設(shè)檢驗可用于監(jiān)控模型性能的漂移,確保系統(tǒng)在真實環(huán)境中保持穩(wěn)定。
應(yīng)用假設(shè)檢驗也需注意潛在挑戰(zhàn)。例如,樣本量不足可能導(dǎo)致檢驗效力低下,而多重比較問題可能增加錯誤發(fā)現(xiàn)的概率。因此,在AI開發(fā)中,結(jié)合其他數(shù)學工具(如貝葉斯方法)和領(lǐng)域知識,才能更全面地評估模型。未來,隨著AI技術(shù)的演進,假設(shè)檢驗將繼續(xù)在可解釋AI和倫理AI中發(fā)揮重要作用,幫助開發(fā)者在復(fù)雜系統(tǒng)中做出數(shù)據(jù)驅(qū)動的決策。
假設(shè)檢驗作為數(shù)學基礎(chǔ)的一部分,為人工智能基礎(chǔ)軟件開發(fā)提供了嚴謹?shù)慕y(tǒng)計支持。通過合理應(yīng)用假設(shè)檢驗,開發(fā)者能夠構(gòu)建更可靠、高效的AI系統(tǒng),推動技術(shù)創(chuàng)新與實際應(yīng)用的無縫銜接。